Method
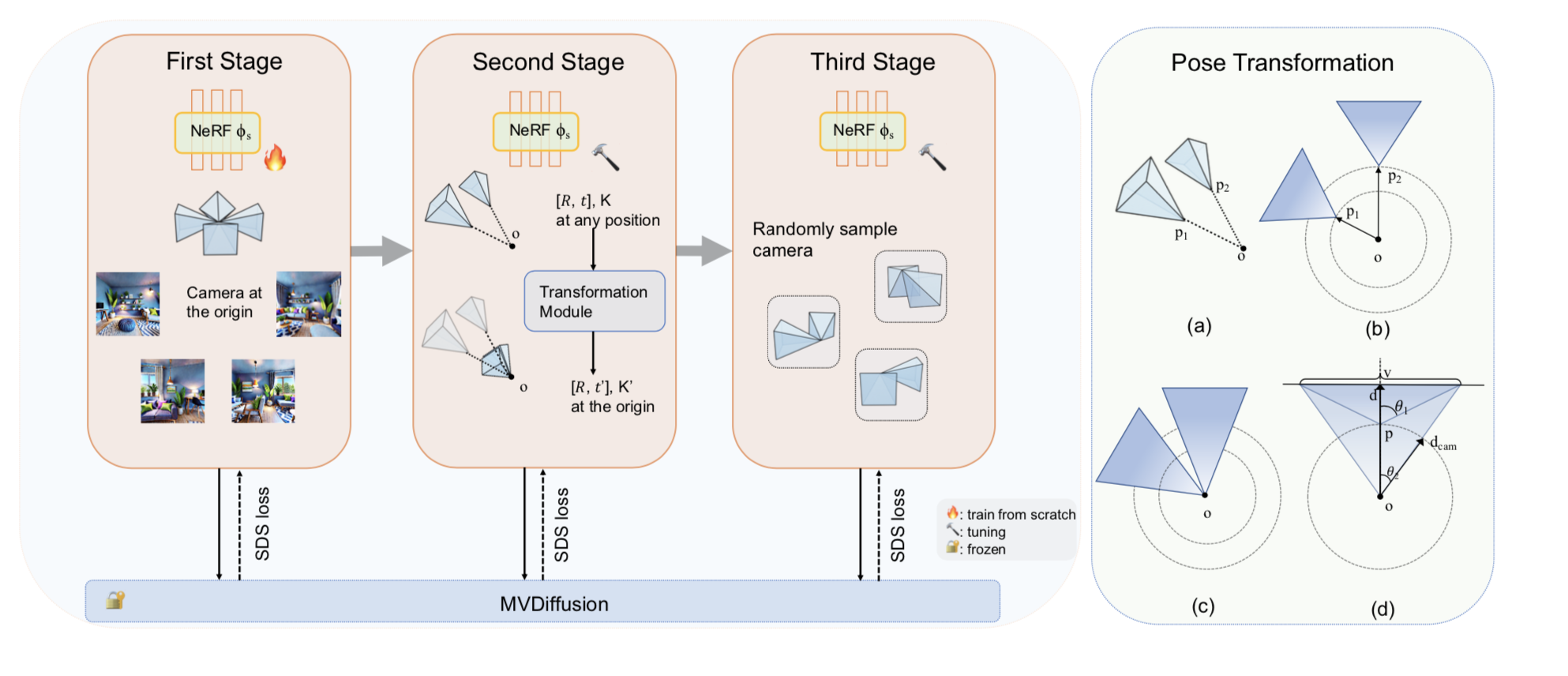
Method overview: Left: Our three-stage training pipeline. First Stage: the camera will be at the center of the room and rotate any degree. Second stage: the camera will be at any position and face outward from the center o. Third stage: the camera will be at any position and rotate any degree. Right: It introduces the pose transformation module in the second stage. (a) shows the camera sampling method in the second stage. p1 and p2 are sampled points at one iteration and o is the center of the room in 3D space. (b) shows the perspective of (a) observed from a 2D plane. (c) shows the two new cameras after the pose transformation. (d) shows the specific scenes observed by the camera at each sampling point. v, dcam, d represent the observed view, the distance from the camera position to the origin and the depth of the view. θ1 and θ2 represent the FOV of two cameras.
Abstract
We introduce ShowRoom3D, a three-stage approach for generating high-quality 3D room-scale scenes from texts. Previous methods using 2D diffusion priors to optimize neural radiance fields for generating room-scale scenes have shown unsatisfactory quality. This is primarily attributed to the limitations of 2D priors lacking 3D awareness and constraints in the training methodology.
In this paper, we utilize a 3D diffusion prior, MVDiffusion, to optimize the 3D room-scale scene. Our contributions are in two aspects. Firstly, we propose a progressive view selection process to optimize NeRF. This involves dividing the training process into three stages, gradually expanding the camera sampling scope. Secondly, we propose the pose transformation method in the second stage. It will ensure MVDiffusion provide the accurate view guidance. As a result, ShowRoom3D enables the generation of rooms with improved structural integrity, enhanced clarity from any view, reduced content repetition, and higher consistency across different perspectives. Exten- sive experiments demonstrate that our method, significantly outperforms state-of-the-art approaches by a large margin in terms of user study.